.png)


As AI-driven developer tools continue to evolve, the foundational architecture of Large Language Models (LLMs) is under intense scrutiny, especially when it comes to maintaining continuity in software development workflows. The increasing complexity of modern codebases, combined with the asynchronous and often long-term nature of real-world development cycles, has pushed the limits of what traditional stateless LLMs can achieve. This has led to a shift in focus toward memory-augmented models, which offer persistent and contextual recall across sessions.
This blog takes a deep dive into the technical distinctions between stateless LLMs and memory-augmented LLMs, focusing specifically on their effectiveness in long-term code understanding, especially in large, dynamic, and collaborative code environments.
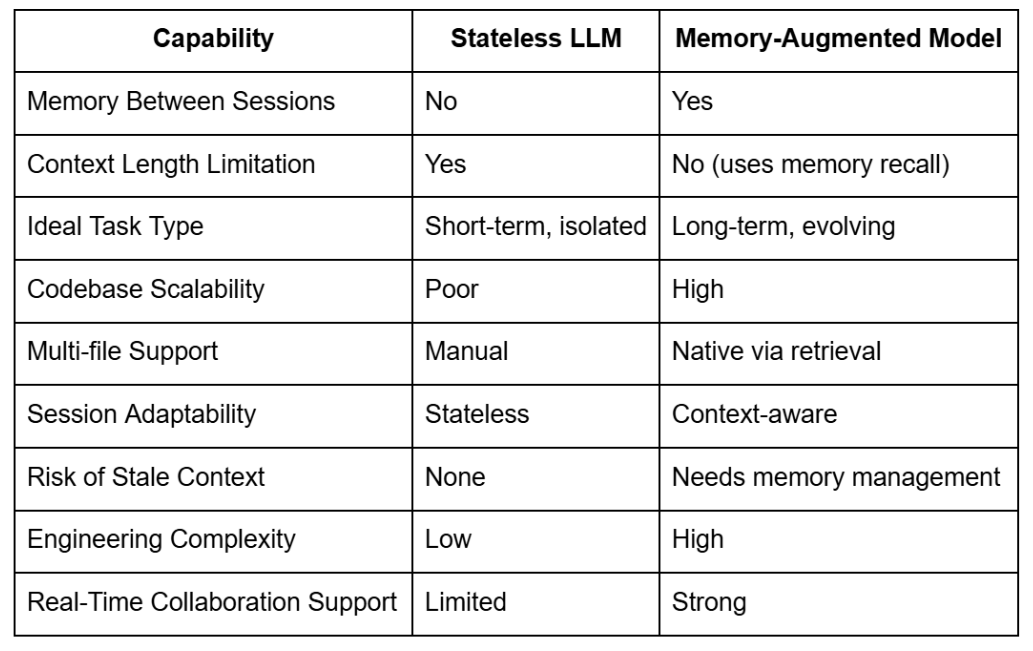
Stateless LLMs operate purely on the input provided at inference time, without maintaining any memory of past interactions, user preferences, or previous states. These models are essentially session-agnostic and only leverage the data explicitly included in the prompt, bounded by their maximum token context window.
Stateless LLMs process each prompt independently, treating it as a complete, self-contained unit of computation. This means that any previous interaction, regardless of how semantically connected it may be, is not remembered unless explicitly included in the new prompt. The implications of this are particularly significant in software engineering contexts, where history, architecture, design rationale, and temporal dependencies matter.
Memory-augmented LLMs (MALLMs) combine the generative capabilities of foundational LLMs with a persistent memory layer. This memory enables them to retrieve, recall, and adapt to information from previous sessions, files, or user interactions, making them more suitable for longitudinal workflows like large-scale software development, architecture design, and continuous integration.
The fundamental limitation of stateless LLMs lies in their lack of continuity. In software development, particularly in large-scale or collaborative environments, long-term understanding is not just a luxury, but a requirement.
Codebases today are distributed across services, domains, modules, and repositories. Stateless models can only operate on the window of tokens they see. This means that unless you explicitly feed them the relevant context — which is not always trivial — they operate with incomplete information.
A change in a protobuf file in a shared schema repository may affect 12 microservices, but unless all those connections are provided manually, the model remains unaware. This makes stateless models prone to generating invalid or outdated suggestions in complex systems.
The illusion of “larger context” is often misleading. Even with extended context windows, the model does not have the ability to semantically organize or prioritize the context unless aided by fine-tuned prompt engineering or retrieval mechanisms. Memory-augmented models outperform by retrieving only what matters, and doing so efficiently.
Stateless models lack the ability to reason about time-based changes or cause-effect relationships in code. If a bug was introduced and later fixed, a stateless model cannot learn from this cycle unless the entire change history is included in the prompt. Memory-augmented systems can store these timelines and use them to suggest preventive measures or historical insights.
To understand their operational distinctions, here is a detailed breakdown:
Let us consider an end-to-end scenario where a developer uses both models over a 10-day development cycle for a feature.
Every step requires manually feeding all relevant context, causing redundancy, inefficiency, and cognitive overload.
This continuity saves developer time, reduces errors, and supports iterative improvement with minimal overhead.
While their benefits are substantial, memory-augmented LLMs also come with implementation and infrastructure challenges.
Memories must reflect the current state of the codebase. If the memory is not updated after a major refactor or dependency change, the model may hallucinate or recommend obsolete code. This requires robust memory invalidation, versioning, and contextual refresh systems.
Memory access introduces latency. Depending on the memory architecture (e.g., vector search across embeddings), response times can increase due to the overhead of retrieving, ranking, and integrating memory content into the final prompt.
Persistent memory needs to be scoped properly, especially in multi-tenant environments. Leaking memory across users or repositories could expose sensitive code or internal logic. Techniques like per-user namespace isolation and memory redaction are essential.
Integrating memory into developer tools is non-trivial. It involves building infrastructure for event-driven indexing, session tracking, file-system watchers, and token-efficient retrieval.
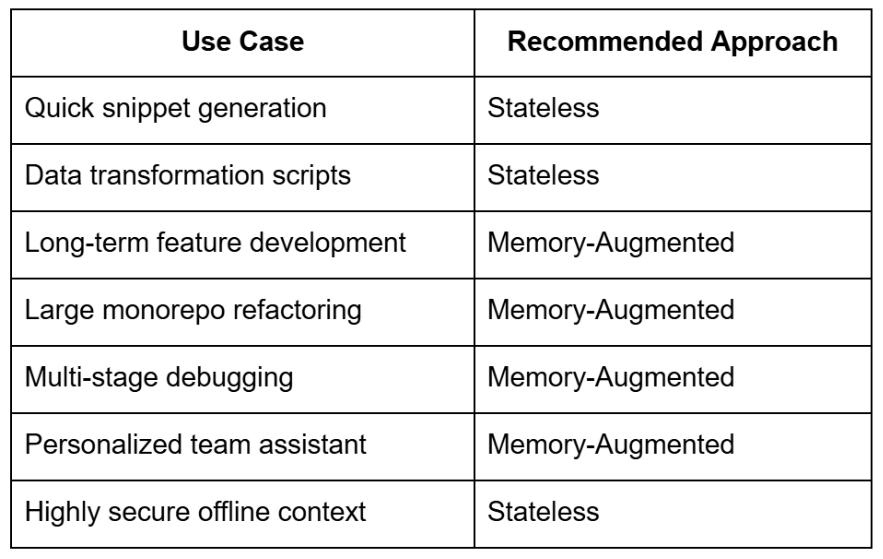
In the current phase of AI tooling for software development, stateless LLMs remain powerful for short, focused tasks. However, the shift toward agentic, memory-backed systems is not just inevitable, it is necessary for scaling intelligence across the lifecycle of modern software engineering.
If your development team works across large codebases, handles multi-step feature delivery, or relies on persistent AI assistance, the architectural limitations of stateless models will become increasingly pronounced. Memory-augmented models unlock the potential for context-aware, personalized, and historically grounded coding assistance.
As platforms like GoCodeo continue to embed memory directly into the development environment, we move closer to an era of AI agents that not only complete code, but understand the systems they help build.




.png)


