.png)


The integration of Large Language Models (LLMs) into development environments has marked a pivotal shift in how modern developers write, analyze, and refactor code. Among these integrations, VSCode stands out as one of the most widely adopted IDEs, offering a rich ecosystem of extensions that embed AI assistance directly into the development workflow. However, developers now face an architectural decision that carries significant implications for performance, security, and user experience: should you use local or cloud-based LLM extensions in VSCode?
In this deep-dive analysis, we explore the intricate technical trade-offs between local and cloud-based LLM extensions. This includes their impact on real-time performance, latency behaviors, system resource utilization, data security, and overall usability. Whether you're an individual contributor working on confidential IP or an enterprise engineer managing CI-integrated workflows, understanding these nuances is critical.
At their core, LLM extensions in VSCode leverage powerful pretrained transformer-based models to assist with various software engineering tasks. These include but are not limited to:
These extensions act as interfaces between your development workspace and a running LLM backend, which could be local or hosted on a cloud server. The underlying model might be a foundational LLM like GPT-4, Claude 3, Mistral 7B, or a fine-tuned variant optimized for code.
Local LLM extensions execute the inference phase of an LLM entirely on your machine. This requires you to download the model weights, often in quantized form such as GGUF or safetensors, and use runtime backends like llama.cpp, mlc-llm, or Ollama. These extensions typically operate as background processes, exposed to the VSCode extension through a local API or IPC protocol.
Local inference eliminates the dependency on network calls, thereby enabling significantly lower latency for code generation. The key performance determinants include:
On local setups, first-token latency can be reduced to around 300-500ms if the model is already loaded into memory. In comparison to cloud-based setups, this offers an advantage for reactive tasks like autocompletion, where sub-second latency is essential for usability.
Once token generation begins, local inference engines such as llama.cpp can deliver 20 to 30 tokens per second depending on model size and quantization level. While this is slower than cloud-inferred models running on A100s or H100s, it is sufficient for most IDE-related tasks.
Local execution places a direct demand on your CPU, GPU, or even Apple’s Metal API if using macOS. To run a 7B parameter model in 4-bit quantization (Q4_0), a system should ideally have:
This becomes a bottleneck if the developer is simultaneously running resource-intensive builds or containerized environments, such as Dockerized microservices or CI pipelines locally.
Local extensions offer full data sovereignty. No part of the prompt, context window, or generated completion leaves your machine. This guarantees:
This is especially critical in regulated industries such as fintech, defense, and healthcare, where sensitive data in source code must be guarded strictly.
A local LLM offers full functionality without any internet connection. This is particularly advantageous for:
Offline operation ensures consistent availability without reliance on remote service uptime or rate limits.
The trade-off of control is operational responsibility. Local LLM extensions often require you to:
While this may be manageable for individual developers, it introduces friction in team environments or CI-heavy workflows.
Cloud-based extensions abstract the LLM execution from the local device by interacting with a hosted API endpoint. These endpoints are typically operated by LLM providers such as OpenAI, Anthropic, or AI-focused startups offering model APIs. Extensions such as GitHub Copilot, GoCodeo Cloud Agent, and CodeWhisperer exemplify this approach.
Cloud-hosted LLMs leverage high-performance GPUs, such as A100s or custom accelerators, ensuring fast token generation. However, performance is gated by network characteristics.
Each completion requires a prompt to be serialized, transmitted, and queued on the server, leading to typical round-trip latencies of 500ms to 1500ms. Latency spikes can occur due to packet loss, transient API downtimes, or vendor-side throttling.
Token generation rates can exceed 60 tokens per second on some cloud setups, making cloud LLMs highly suitable for long-form generation tasks or large context windows.
A key benefit is that cloud extensions are computationally lightweight. They:
This makes them suitable for developers working on lower-powered laptops or remote VM sessions.
Cloud-based extensions introduce a non-trivial attack surface due to data transmission. Key risks include:
Some vendors offer enterprise plans with encryption guarantees and opt-out clauses, but trust boundaries still exist. In multi-tenant cloud infrastructures, even sandbox isolation is not infallible.
Cloud extensions tend to offer more polished UX due to:
They also integrate seamlessly with online services such as GitHub, GitLab, and CI systems, allowing end-to-end workflows inside the IDE.
Cloud extensions offer high scalability without any local maintenance burden. Benefits include:
For organizations managing large teams, this offloads significant DevOps and MLOps overhead.

While local models excel in reactive latency, cloud LLMs offer higher throughput and scalability, especially with large prompts.
For developers handling proprietary codebases, cloud-based extensions may pose risks that violate NDA or compliance frameworks. Conversely, local extensions eliminate data exfiltration risk but require stringent endpoint hardening to prevent leaks.
A hybrid architecture might use local inference for secure code and cloud models for open-source or scaffolding tasks, ensuring the best of both worlds.
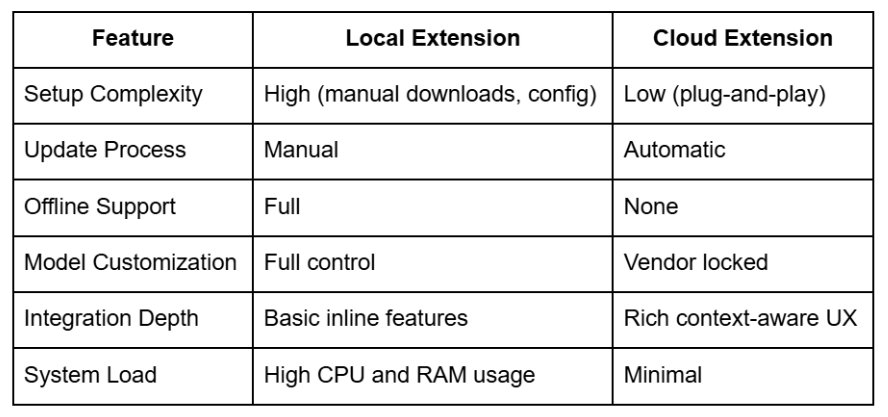
Each approach optimizes for different personas. A power user might prefer local control, while a frontend developer might lean toward plug-and-play speed.
Choosing between local and cloud-based LLM extensions in VSCode involves a nuanced evaluation of security, speed, and developer ergonomics. As LLMs continue to evolve, the performance gap between local and cloud setups is narrowing, especially with the rise of efficient inference engines and smaller, instruction-tuned models. Meanwhile, cloud vendors continue to innovate on integration depth and inference efficiency.
The ideal setup might be hybrid, where local extensions are used during confidential project work and cloud extensions are used for rapid prototyping or open-source contributions. Developers and teams should evaluate their threat models, performance needs, and operational constraints before committing to either architecture.




.png)


