.png)


The integration of AI code generators into CI/CD pipelines is reshaping the automation landscape for software development teams. Traditionally, CI/CD pipelines have focused on deterministic automation tasks such as running unit tests, building artifacts, deploying services, or validating infrastructure configuration. With the emergence of AI code generation capabilities powered by large language models, it is now possible to bring intelligent, contextual, and adaptive automation to various stages of the software delivery lifecycle.
In this blog, we will deeply examine the specific touchpoints where AI code generators can be embedded into CI/CD workflows, the technical patterns and tools that enable such integrations, and how to implement them in production-grade environments while maintaining high confidence, reproducibility, and auditability. The blog is written with the intent to assist experienced developers, DevOps engineers, and platform teams in understanding the architectural strategies and operational best practices for embedding AI-driven code generation inside CI/CD pipelines.
One of the major benefits of using AI code generators in CI/CD pipelines is the significant reduction in manual effort and repetitive tasks. AI can augment the developer’s productivity by suggesting boilerplate code, generating missing test cases, updating configuration files, or even fixing simple bugs automatically based on the context of recent changes. By integrating this automation within CI/CD pipelines, teams can ensure that each commit is automatically enhanced and verified without manual intervention.
As repositories scale, technical debt accumulates silently. AI models trained on best practices and coding standards can help mitigate this by continuously suggesting better patterns, refactoring unoptimized code, or enforcing consistency across modules as part of CI checks. Developers no longer have to schedule dedicated “refactor sprints” because such improvements are introduced incrementally during every pipeline run.
AI code generation embedded early in the lifecycle, for example, at the pre-commit or pre-merge phase, enables the “shift-left” principle to go beyond static analysis and linting. It can bring contextual suggestions, test code generation, and documentation enhancements directly into the developer feedback loop, thereby improving code quality and reducing post-deployment issues.
Pre-commit hooks are an ideal stage for lightweight, low-latency AI interventions. At this phase, the changes are still local to the developer, and thus any AI-generated suggestions or corrections can be reviewed and modified before entering the CI pipeline. These hooks can be custom scripts or integrated via tools like pre-commit which orchestrates various hooks written in Python, Bash, or other languages.
Imagine a developer modifying a Python module. Before committing, a hook runs that analyzes the diff and uses an AI model to suggest inline docstrings, apply formatting rules based on the team’s coding standards, or refactor long functions for readability.
#!/bin/bash
files=$(git diff --cached --name-only --diff-filter=ACM | grep '\.py$')
for file in $files
do
ai_linter --path $file --mode refactor --model gpt-4 --output-fix
done
This ensures that AI refactoring occurs on modified files only, and modifications are staged back after the fix, minimizing merge conflicts.
CI pipelines triggered on pull request events are suitable for heavier AI workloads. Here, AI agents can perform contextual understanding of code diffs, retrieve historical patterns from the repository, and suggest comments or even auto-generate commits containing improvements.
This can be achieved using custom GitHub Actions or GitLab CI jobs that consume the pull request diff, extract relevant context, and invoke an AI model via API. The result is either posted back as a comment or committed as a separate branch.
- name: AI Code Review
run: |
diff=$(git diff origin/main...HEAD)
python ai_review_agent.py --diff "$diff" --token ${{ secrets.AI_API_KEY }}
The Python script would internally parse the diff, infer high-level intentions, match known anti-patterns, and return suggested improvements. These may include better naming conventions, missing null checks, or replacing legacy APIs.
This model empowers teams to scale code review coverage, maintain consistency in large teams, and reduce review fatigue. More importantly, it can surface suggestions even before a human reviewer sees the pull request.
Manual test writing remains one of the most under-addressed bottlenecks in software development. Especially in fast-paced deployments, test coverage often lags behind code changes, leading to undetected regressions.
By leveraging AI models trained on programming languages and test generation techniques, it is now feasible to generate:
During the CI stage, after code is checked out and dependencies are installed, a dedicated job can:
changed_files=$(git diff --name-only origin/main | grep '\.py$')
python generate_tests.py --files "$changed_files" --mode ai
pytest tests/generated/
Tests generated by AI should be clearly separated from human-authored tests, ideally under a separate test suite or tag. This allows teams to monitor false positives, flaky tests, or incomplete assertions and incrementally improve prompt engineering or model tuning.
DevOps teams often deal with complex IaC artifacts including Terraform, Helm Charts, Kubernetes manifests, and Pulumi programs. These are often error-prone due to schema changes, environment differences, or policy violations. AI can validate these files against:
Once a terraform plan or kubectl diff is generated, its output can be converted to JSON or structured text and sent to an AI model that understands configuration semantics.
- name: Run Terraform Plan
run: terraform plan -out=tfplan && terraform show -json tfplan > plan.json
- name: Validate Plan Using AI
run: python validate_plan.py --input plan.json --ai-token ${{ secrets.AI_API_KEY }}
AI-generated suggestions must be reviewed by DevSecOps teams, and should never auto-apply changes or overrides. The goal is to enrich validation feedback, not bypass human judgment.
In the post-deployment stage, especially in Canary or Blue-Green deployments, AI agents can monitor logs, application metrics, and event streams to:
This creates a feedback loop where AI doesn't just generate code, but also interprets the results of code execution, enabling self-healing or proactive engineering responses.
AI-generated code is inherently stochastic, but for production CI pipelines, determinism is crucial. Techniques to improve predictability include:
When calling AI APIs from CI/CD, account for:
Every AI-generated artifact should include metadata such as:
This ensures that teams can trace how a given line of code was generated and under what context.
AI-generated code must be treated as untrusted. Best practices include:
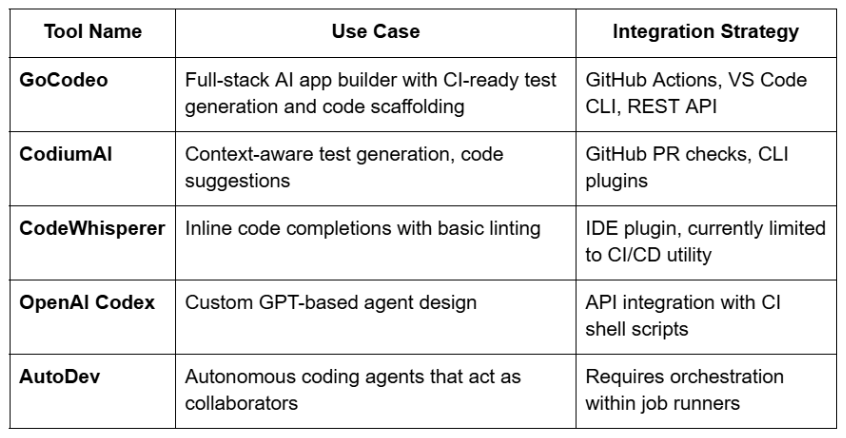
name: AI Powered Code Workflow
on:
pull_request:
branches: [main]
jobs:
generate-and-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Generate Tests Using GoCodeo
run: |
changed_files=$(git diff --name-only origin/main)
goCodeo generate-tests --files "$changed_files" --output ./tests/generated/
- name: Run AI Generated Tests
run: |
pytest ./tests/generated/
This pipeline automatically generates test cases for newly committed modules and executes them, providing early feedback and improving test coverage without manual effort.
The integration of AI code generators in CI/CD pipelines is no longer a theoretical capability, it is a practical enhancement adopted by high-performing teams. It enables real-time automation of test generation, code refactoring, config validation, and post-deployment analysis, without requiring developers to write custom logic for every use case.
However, successful implementation requires careful design, monitoring, and guardrails. AI is not a magic black box, but a tool that needs boundaries, observability, and human oversight. When embedded with precision, AI-powered pipelines can become your strongest ally in shipping higher-quality software at scale.




.png)


