.png)


Artificial Intelligence integrations inside Visual Studio Code, or VSCode, have rapidly evolved from simple autocomplete engines to sophisticated AI coding agents capable of generating multi-file implementations, writing tests, refactoring codebases and even debugging in real-time. Tools like GitHub Copilot, Cursor, GoCodeo, CodeWhisperer, and other LLM-backed extensions are increasingly used by developers to accelerate software development workflows. However, despite the clear productivity gains, there are underlying concerns that are often left unaddressed, particularly regarding model privacy and token usage.
At the heart of every AI-powered extension lies an interaction model between the developer's local environment and remote large language models. These interactions are not trivial, as they involve transmitting sensitive code, capturing user context, and consuming tokens that incur both financial and computational cost.
This blog dissects how VSCode AI extensions are architected, what data is transmitted to external servers, how token metering works, and what developers can do to evaluate and mitigate associated risks. Whether you are evaluating a new tool, integrating a model yourself, or deploying these solutions within an enterprise codebase, this breakdown will help you make informed technical decisions.
To understand how model privacy and token usage play out, it is essential to first dissect how typical VSCode AI extensions are architected. These tools generally consist of three loosely coupled components: the local extension layer, the communication and routing layer, and the remote model-serving infrastructure.
When you install an AI extension in VSCode, the code executes in the Extension Host, which is a sandboxed Node.js environment within the editor itself. This component has access to a variety of VSCode APIs, which allow it to monitor:
The extension host is where context for a prompt is constructed. Based on user activity such as typing or executing a command, the extension gathers relevant information, including current file contents, surrounding lines, symbols from the workspace, and sometimes multiple files if the request involves cross-file analysis. This context is not inherently private, as it is sent outside the local environment in the next stage.
Once the extension has constructed a prompt or input context, this data must be serialized and transmitted to a model endpoint. This typically involves an HTTP(S) API call to either:
This is the critical point where private code leaves the developer’s machine. If TLS is used, transmission is encrypted in transit, but there are still risks at the model endpoint if it logs requests, caches results, or uses the prompts for training without developer consent.
The model server hosts the actual large language model, such as GPT-4, Claude, or Code Llama. The server receives the prompt and responds with a generated completion, function call, explanation, or whatever behavior the extension has initiated. This step is typically opaque to the developer unless the extension offers a transparent inspection mechanism for API payloads.
Each interaction with the model consumes tokens, which we will cover in depth later. The number of tokens sent and received correlates with both cost and potential surface area for data exposure.
The breadth and depth of data sent from your local VSCode environment to a remote AI model depend on the extension’s internal design and your active configuration. While many developers assume only their immediate input is sent, modern extensions often construct a rich context window from a variety of sources.
Most extensions automatically include the contents of the file currently being edited. Some allow configuration of how many lines before and after the cursor are included. Others, particularly codebase-aware tools, may send the entire file.
If autocomplete or inline suggestions are active, the extension may re-transmit new versions of the file as the developer types, increasing token usage and widening the data exposure window.
Context-aware extensions like Copilot or GoCodeo may extract the file tree, module imports, dependency graphs, and even function usage to provide better completions. These details, while valuable for AI-driven suggestions, may leak architectural patterns or proprietary logic.
When a developer invokes a specific command such as "generate unit tests for this function," the extension extracts not only the targeted function but also adjacent functions, class definitions, and comments to provide semantic context. This can result in transmission of large code blocks that are indirectly relevant.
In-chat extensions, user-entered prompts are fully sent to the LLM, often alongside system prompts or instructions configured by the extension vendor. These prompts may include references to internal documentation, issue numbers, or business-specific terminology.
Some extensions transmit metadata such as project names, filenames, timestamps, or VSCode session IDs. If telemetry is not opt-in, this data can be logged for analytics, which increases the privacy attack surface.
Token usage is a fundamental concern when evaluating the operational cost and privacy impact of LLM-based tools. Tokens represent the unit of billing for nearly all commercial LLM APIs and determine how much data is exposed during each interaction.
Tokens are not equivalent to characters or words. Instead, they represent chunks of text, typically aligned with subword units. A simple rule of thumb is that 1,000 tokens is approximately 750 English words or 4,000 characters. However, this varies depending on the tokenizer used by the model.
For example:
ts
// Roughly 12 tokens
function multiply(a, b) {
return a * b;
}
Each API call counts both input tokens (prompt length) and output tokens (response length). Costs accrue for both directions.
Commercial APIs such as OpenAI's charge per 1,000 tokens, with different rates for prompt and completion tokens. Developers often overlook how fast tokens can accumulate, especially in tools that continuously stream code context in the background.
For instance, if your editor sends 1,200 input tokens every 5 seconds during typing, and you work for 1 hour, the cumulative usage can exceed 100,000 tokens, even without explicit prompts.
The larger the prompt window, the more code is exposed to the remote model. Extensions that aggressively include project-wide context, recent file history, or verbose system instructions increase this risk. Developers must weigh the trade-off between suggestion quality and data minimization.
This table presents a comparative overview of popular extensions. All data is based on publicly available documentation and observed behaviors.
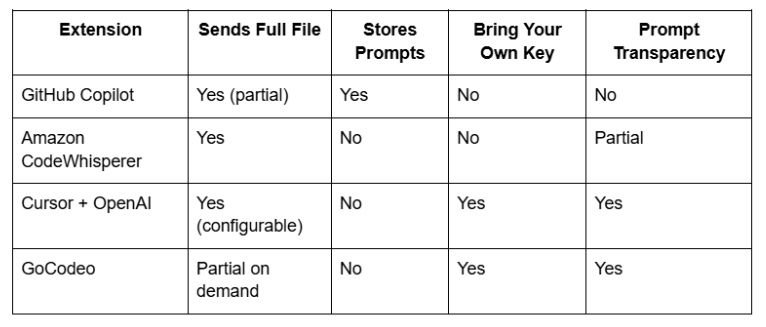
Developers should prioritize extensions that:
Developers interested in gaining operational visibility into these extensions can use a variety of tools and strategies to audit how much data is being sent, where it is sent, and how tokens are being counted.
Install a transparent proxy like mitmproxy or use a tunneling tool like ngrok to capture API traffic. This allows developers to inspect raw payloads, including headers, request bodies, token count estimates, and endpoints.
For APIs like OpenAI, set up API usage dashboards or rate limit alerts. This helps detect unintended background consumption, such as excessive token usage during passive editing.
When using custom models or API wrappers, truncate code context by:
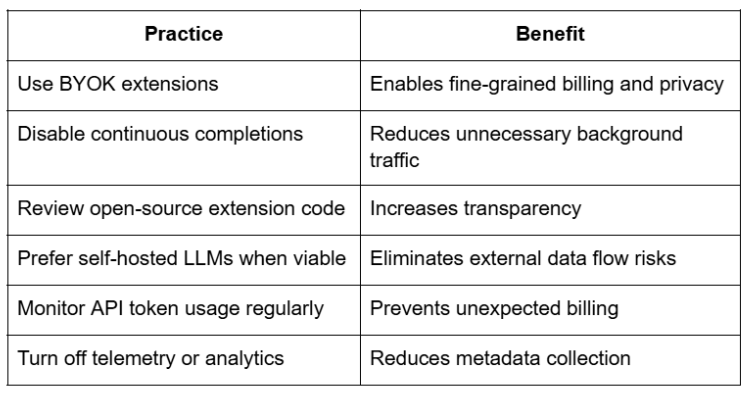
Evaluating model privacy and token usage is no longer optional for developers integrating VSCode AI extensions into their workflows. With the increasing presence of AI agents in daily development pipelines, understanding what code is sent, how frequently, and to whom, becomes a security and cost imperative.
As a developer or team lead, your responsibility is to:
In a world where AI is shaping how we write code, the right tooling choices today will define the security and efficiency of tomorrow’s software systems.




.png)


