.png)


Modern AI systems are transitioning from passive, single-turn LLM interfaces into active agents that operate over extended timelines, interact with external tools, and synthesize information from diverse sources. These systems are expected to make coherent, goal-oriented decisions based on a variety of dynamic inputs. This brings forth a highly complex technical challenge, one that centers around a critical capability: reasoning across multiple inputs and evolving contexts.
This blog provides a comprehensive guide for developers who are architecting intelligent agents capable of advanced context integration and reasoning. We will break down the architectural principles, input modeling strategies, memory design techniques, execution planning loops, and evaluation methods required to enable AI agents to operate effectively in real-world, multi-source environments.
Traditional LLMs function as stateless models, limited by the context window and lacking long-term memory or awareness of external processes. When building agents, we are no longer dealing with a simple prompt-to-response mechanism. Instead, we require a system that can:
These requirements demand a move toward compositional architectures, where memory, reasoning, input handling, and execution are modular yet integrated. The agent must maintain a consistent understanding of task objectives and environmental changes, even as new data is introduced or external dependencies evolve.
One of the most foundational components in the architecture of reasoning-capable AI agents is memory. Unlike LLM-only solutions, agents require structured memory to persist key-value information, retrieve semantically relevant past data, and index contextual elements of interactions over time. Here are some memory models typically implemented in production systems:
Episodic memory involves storing snapshots of each decision point or interaction. Each episode can contain input-output pairs, tool invocations, environment states, or user prompts. This memory type allows agents to trace back their actions and evaluate consistency, which is particularly useful in debugging and plan revision.
By encoding textual, image, or code data into high-dimensional vector embeddings, semantic memory allows agents to recall related items based on proximity in the latent space. Tools such as FAISS, Weaviate, and Qdrant are widely used for embedding storage and nearest neighbor retrieval.
Most high-functioning agents employ a hybrid memory approach, combining symbolic memory (such as dictionaries, maps, and relational tables) for deterministic lookup and semantic memory for flexible recall. The decision of which type of memory to use is based on data type, volatility, and recall requirements.
Developers must implement memory scopes to manage session-based, task-based, and long-term persistence. This can be achieved by tagging memory entries with TTLs (Time To Live), scoping keys by user session IDs, or classifying memories based on relevance feedback loops.
AI agents rarely operate on natural language alone. In real-world applications, agents must process inputs that range from structured JSON data and API responses to visual content, audio, logs, telemetry, and user-uploaded files. To support this, the system must contain an Input Abstraction Layer capable of ingesting, normalizing, and encoding heterogeneous data.
Each incoming input must be transformed into a format the agent can reason over. For instance:
Every input needs to be encoded using an appropriate encoder and tagged with metadata, such as:
This metadata becomes crucial for context routing and attention filtering, ensuring that the agent reasons primarily over the most relevant and recent inputs.
To unify different modalities, embedding alignment must be implemented. This includes training adapters or using pre-trained multi-modal transformers that project data into a shared latent space. Additionally, developers can use co-attention layers or cross-encoder models to jointly reason across multiple aligned inputs.
In systems with multiple concurrent inputs, not every piece of information is equally relevant. Agents must make intelligent decisions about what to attend to, what to store for later, and what to ignore. This is accomplished using context routing policies.
Inputs can be scored using various criteria, such as:
Routing policies can be implemented using rule-based heuristics, reinforcement learning, or even meta-models trained to score importance.
In advanced agent architectures, inputs are routed into different subsystems, such as:
Developers can also implement query planners that select which memory entries or external tools to query before forming the next response.
LLMs are limited by the information encoded in their weights and the size of their context windows. To overcome this, reasoning agents invoke external tools, APIs, or services dynamically.
Agents must maintain a registry of callable tools with the following properties:
This registry is typically maintained as a structured schema or defined using OpenAPI specs.
Using models like ReAct or planning agents like LangGraph or AutoGen, developers can build agents that reason using tool results. Each step of the chain is validated, contextually evaluated, and then fed into the next.
This recursive composition allows for complex multi-hop reasoning:
For agents to operate reliably, they must maintain internal state across turns and sessions. This includes knowledge of:
Sessions should be scoped using unique identifiers, with memory, context, and logs scoped to that session. Persistent storage mechanisms such as Redis, DynamoDB, or Postgres are often used to retain agent state across restarts.
Every decision made by the agent should be logged as a chain of reasoning steps. These logs not only aid debugging but also allow the agent to explain its behavior. Tools like PromptLayer or Traceloop can be used to track and visualize these logs.
Evaluating agents that reason across contexts cannot rely solely on output correctness. Developers must measure:
A full instrumentation layer should log all prompt compositions, tool calls, memory lookups, and error handling decisions. This enables reproducible debugging, metric tracking, and model refinement over time.
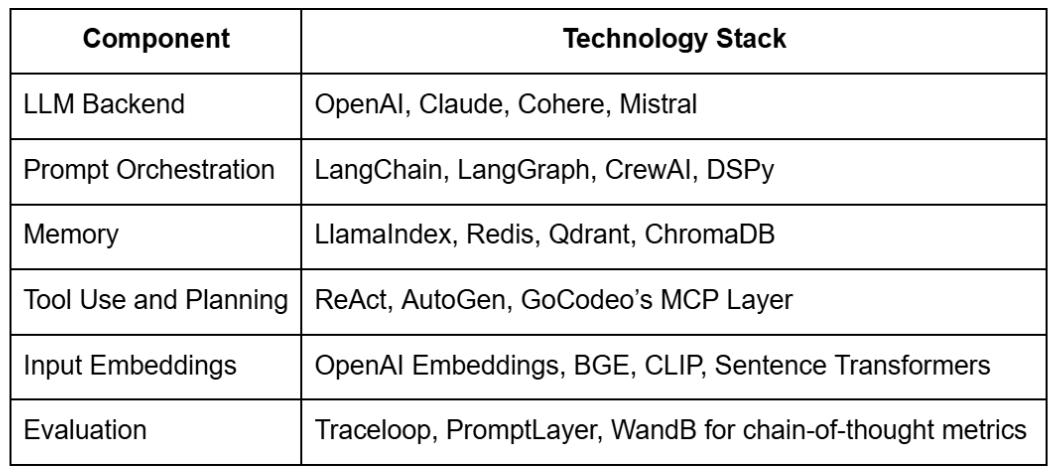
GoCodeo implements a full-stack coding agent that builds production-grade apps by reasoning over:
This is orchestrated via:
This system maintains continuity, handles tool failures gracefully, and operates in a context-rich environment to deliver consistent engineering-grade output.
Designing AI agents that can reason across multiple inputs and contexts requires systems engineering at multiple levels. From memory management to input fusion, from planning logic to tool invocation, each layer must be deliberately architected.
As developers, we must view agent design not just through the lens of prompting, but through modular, reactive, memory-augmented architectures. These systems must be resilient, transparent, and able to scale across varied tasks and domains.
In a world moving toward autonomous agents and complex orchestration, the ability to design context-aware, multi-input reasoning agents will define the next generation of AI applications.




.png)


